读完 DeepSeek-V4 技术报告:这次最值得看的,不是“更大”,而是“更省”
先说清楚边界。本文只基于 deepseek-v4/DeepSeek_V4.pdf,不补 PDF 外的传闻,也不把报告里没有展开的内容写成确定结论。
如果只用一句话概括,我会这么说:DeepSeek-V4 要解决的核心问题,不是“参数再大一点”,而是模型真的开始跑超长上下文、长链路推理和复杂工具调用时,传统 attention 的成本会先撑不住。V4 的很多改动,最后都指向同一个问题:1M context 到底怎样才能跑起来,而且别贵得离谱。(原文第 4-5 页)
文中提到的“原文第 X 页”,都对应 DeepSeek_V4.pdf 的 PDF 页码。中文写作、white-collar task、code agent 这些结果,多数来自报告里的 internal evaluation,更适合看作“官方自测结果”,不应直接等同于第三方独立评测。(原文第 43-44 页、第 57-58 页)
1. V4 一上来谈的不是排名,而是超长上下文的成本
原文对应:第 4-5 页。
我读这份 PDF 时,第一个明显感受是:它开头没有急着讲 benchmark,也没有先铺“模型多强”。它先把问题摆出来。
报告的说法是,reasoning model 带来了 test-time scaling 的新范式,但 vanilla attention 的 quadratic complexity 会在 ultra-long context 和 reasoning process 里变成明显瓶颈。同时,复杂 agent workflow、跨文档分析这类 long-horizon task 会越来越重要,所以“高效支持超长上下文”已经不是锦上添花,而是后续能力继续往上走的前提。
随后,报告给出模型规格:
DeepSeek-V4-Pro:1.6T参数,每个 token 激活49BDeepSeek-V4-Flash:284B参数,每个 token 激活13B- 两者都支持
1 million tokens的 context length
这里的重点不只是“大”。按 PDF 的说法,目标是 “break the efficiency barrier of ultra-long-context processing”。说白了,窗口变长还不够。长了以后还能不能用、能不能稳定用、成本能不能接受,才是这份报告真正关心的问题。(原文第 4 页)
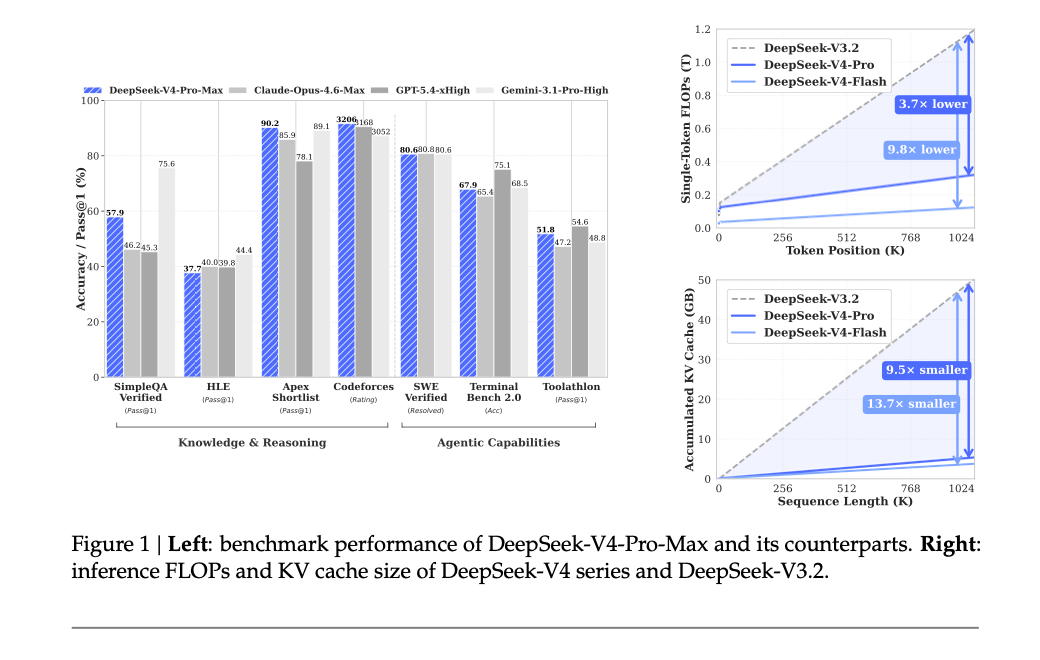
原文第 1 页 Figure 1:左侧是 DeepSeek-V4-Pro-Max 与 Claude、GPT、Gemini 的 benchmark 对比;右侧是 DeepSeek-V4 系列相对 DeepSeek-V3.2 的 inference FLOPs 和 KV cache 变化。
2. 它没有推倒重来,而是把最贵、最难的几处一起改了
原文对应:第 4-7 页。
很多人看到新版本,会下意识问:是不是整套架构都换了?PDF 给出的答案很清楚,V4 不是这条路线。
Transformer 主体还在,DeepSeekMoE 还在,Multi-Token Prediction 也还在。真正的变化,主要集中在三件事:
- 用
mHC强化传统 residual connection - 用
CSA + HCA组成 hybrid attention,专门处理长上下文效率 - 用
Muon作为主要优化器,提高收敛速度和训练稳定性
只看这三条,可能会觉得它还是一次常规模型升级。但 PDF 后面又列了一串基础设施改造,意思就出来了:V4 不是在模型层加几个新组件,而是把架构、优化器、kernel、并行和 cache 管理一起收紧。
- 为 MoE 设计单个 fused kernel,尽量重叠 computation、communication 和 memory access
- 用 TileLang 开发高性能 kernel,同时兼顾开发效率
- 建 batch-invariant、deterministic 的 kernel library,追求 bitwise reproducibility
- 在 MoE expert weight 和 indexer QK path 上做 FP4 quantization-aware training
- 给训练和推理分别补上更细的 checkpointing、parallelism 和 KV cache 管理
所以按这份技术报告自己的写法,DeepSeek-V4 不是“堆了几个新名词”,而是把一整条链路重新拧紧了。(原文第 4-7 页)
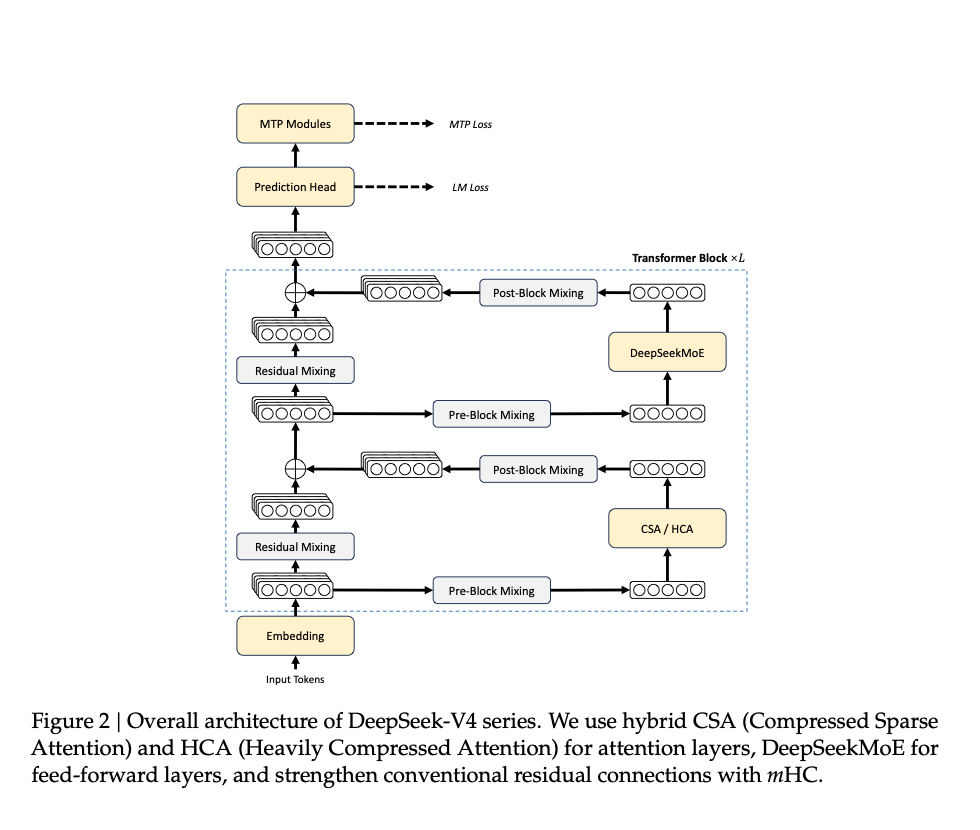
原文第 6 页 Figure 2:attention 层换成了 CSA / HCA,前馈层仍然是 DeepSeekMoE,残差路径里加入 mHC,顶部保留 MTP。
3. 核心还是 attention:先压缩,再筛选,再补局部细节
原文对应:第 9-11 页、第 25 页。
如果只能在 V4 里挑一个最值得细看的部分,我会选 hybrid attention。原因很简单:它正面回应了开头提出的那个问题。上下文一长,attention 就会变成主要计算瓶颈。
PDF 给出的做法,是把 attention 拆成两种形态,交替出现:
Compressed Sparse Attention (CSA)Heavily Compressed Attention (HCA)
3.1 CSA 在做什么
按 PDF 的定义,CSA 分两步:
- 先把每
m个 token 的 KV cache 压缩成一个 entry - 再做 DeepSeek Sparse Attention,让每个 query token 只看
top-k个 compressed KV entry
但它没有把局部信息一刀切掉。报告还写到,除了这些被挑中的 compressed KV entry,CSA 会再接上一小段 sliding window KV entry,用来保留局部细粒度依赖。
换成人话,大概就是:先把很长的上下文做成一层“摘要索引”,再从里面挑最相关的块来看,同时保留眼前这一小段原始细节。它不再让每个 token 都把整段历史重新扫一遍。
参数列得也很细。
对 DeepSeek-V4-Pro:
m = 4top-k = 1024- indexer query heads =
64 - indexer head dimension =
128 - query heads =
128 - head dimension =
512 - query compression dimension =
1536 - sliding window size =
128
对 DeepSeek-V4-Flash:
m = 4top-k = 512- indexer query heads =
64 - indexer head dimension =
128 - query heads =
64 - head dimension =
512 - query compression dimension =
1024 - sliding window size =
128
3.2 HCA 在做什么
HCA 的目标更直接:继续压 KV cache。PDF 的表述是,HCA 使用更大的 compression rate m',但不再做 sparse attention,而是保留 dense attention。
两个模型的 HCA 配置都是:
m' = 128
所以如果只按 PDF 的设计分工来理解:
- CSA 更像“先压缩,再挑重点看”
- HCA 更像“先压得更狠,然后继续做 dense attention”
两者交替出现,再配合 sliding window attention,构成 V4 的 hybrid attention 路径。(原文第 9-11 页)
3.3 结果是什么
报告在第 5 页给了最直接的一组数字。在 1M-token context 下,相比 DeepSeek-V3.2:
DeepSeek-V4-Pro的 single-token inference FLOPs 降到27%DeepSeek-V4-Pro的 KV cache size 降到10%DeepSeek-V4-Flash的 single-token inference FLOPs 降到10%DeepSeek-V4-Flash的 KV cache size 降到7%
这组数字很关键。它说明 V4 不是把窗口勉强拉到 1M 就结束,而是想把 1M context 变成一个可以长期使用的设定。Figure 1 右边两张图讲的也是这件事。(原文第 5 页)
4. mHC 没有 attention 抢眼,但管的是底层稳定性
原文对应:第 7-8 页。
attention 是主角没错,但 PDF 给 mHC 的篇幅也不少。原因不难理解:模型越深,训练里最怕的往往不是“想法不够新”,而是数值先不稳。
报告先回顾了普通 Hyper-Connections。它的做法是把 residual stream 的宽度扩到 n_hc 倍,再引入输入映射、残差映射和输出映射。问题是,PDF 明确说 naive HC 在多层堆叠时会频繁出现 numerical instability。
DeepSeek-V4 采用的是 Manifold-Constrained Hyper-Connections (mHC)。核心改动,是把 residual mapping matrix 约束到 doubly stochastic matrices 的 manifold,也就是文中提到的 Birkhoff polytope。
PDF 给出的解释有三点:
- 这个约束会把 mapping matrix 的 spectral norm 限制在
<= 1 - 所以 residual transformation 是 non-expansive 的
- 这会提升 forward pass 和 backpropagation 中的 numerical stability
换句话说,mHC 的目标不是“让残差连接更花哨”,而是尽量防止信号在深层传播时越传越失控。
PDF 还补了两个实现细节:
- doubly stochastic 矩阵集合在矩阵乘法下仍然闭合,适合 deep stack
- 他们用
Sinkhorn-Knopp algorithm做行列归一化投影,t_max = 20
所以 mHC 在 V4 里更像一块稳定性部件。它可能没有 benchmark 数字那么显眼,但如果这里压不住,后面很多训练收益都未必站得住。(原文第 7-8 页)
5. 这份报告很工程化,因为 1M context 不是只靠公式落地的
原文对应:第 15-17 页、第 23-24 页。
我读 V4 这份 PDF 时,另一个感受是:它花了很多篇幅讲 kernel、并行、cache 和可复现性。这不是闲笔。长上下文模型如果真的要训练、部署、复现,系统层不是配角。很多时候,它就是决定模型能不能跑起来的那一层。
5.1 MoE 的 fused kernel 和 Expert Parallelism
general infrastructures 这一章里,报告重点谈的是 expert parallelism 的通信瓶颈。应对方法主要有三步:
- 把 communication 和 computation 融合进单个 pipelined kernel
- 把 experts 再切成更细的 waves
- 让当前 wave 的计算、下一 wave 的 token transfer、已完成 expert 的结果发送并行进行
对应结果是:
- 对一般 inference workload,速度提升
1.50x到1.73x - 对 RL rollout 和 high-speed agent serving 这类更吃延迟的场景,最高到
1.96x
PDF 还给了一个很工程化的判断标准:通信能不能被计算完全遮住,不只看带宽,也看 computation-communication ratio。对 DeepSeek-V4-Pro,报告把平衡条件写成 C / B <= 2d = 6144 FLOPs/Byte。(原文第 16 页)
5.2 TileLang、Host Codegen 和 bitwise reproducibility
报告单独拿出一节讲 TileLang。理由很直接:V4 的复杂架构如果继续拆成很多零碎的 Torch ATen operator,开发效率和运行效率都会受影响,所以他们用 TileLang 来写 fused kernel。
另外,PDF 提到 Host Codegen 会把不少 host-side logic 从 Python 路径挪到生成代码里,结果是:
- CPU-side validation overhead 从几十到上百微秒,降到每次调用不到
1微秒
还有个细节不能漏:报告专门强调 numerical precision 和 bitwise reproducibility。也就是说,他们不只是想“跑得快”,也在追求训练和推理结果的一致性。(原文第 17 页)
5.3 KV cache layout 和 on-disk storage
V4 的 inference framework 也不是把传统 KV cache 直接放大。PDF 说他们设计了 heterogeneous KV cache structure,把缓存分成两类:
- classical KV cache:给 CSA/HCA 的 compressed KV 使用
- state cache:给 SWA 和尚未完成压缩的 tail token 使用
在 on-disk KV cache reuse 上,报告给了三种 SWA KV 管理策略:
Full SWA CachingPeriodic CheckpointingZero SWA Caching
PDF 对这三种方案的解释也很明确:它们对应不同的 storage overhead 和 recomputation 取舍,部署时按场景选。(原文第 23-24 页)
6. 训练节奏很克制:不是一开始就把 1M 和 sparse attention 全打开
原文对应:第 25-27 页。
只看训练设置,V4 的节奏其实很清楚。它不是一步跳到最终形态,而是分阶段推进。
6.1 预训练怎么拉长序列
报告给出的训练 token 数是:
Flash:32TPro:33T
两者的 sequence length 都是逐步扩展:
4K16K64K1M
PDF 还专门写到,Flash 在前 1T tokens 先使用 dense attention,等 sequence length 到 64K 以后再引入 sparse attention;Pro 也采用类似的 two-stage 方法,只是 dense attention 阶段更长。
这段安排的意思很朴素:即便目标是 1M context,训练也没有一上来就切到最复杂配置,而是先在更稳定的条件下把基础能力长起来,再逐步切到更适合长上下文的结构。
6.2 优化器和稳定性技巧
optimizer 方面,PDF 的写法是:
- 大多数参数使用
Muon - embedding、prediction head 和 RMSNorm weight 使用
AdamW
除此之外,报告还单独列了两个稳定性技巧。
第一个是 Anticipatory Routing。PDF 的解释是,在 step t 做 feature computation 时,routing index 用历史参数 theta_(t - delta_t) 来算。实现上,会提前计算并缓存 routing index,并通过自动检测机制,只在出现 loss spike 时短时开启这个模式。
报告给出的代价和结果是:
- 额外 wall-clock overhead 约
20% - 因为只在异常阶段动态触发,整体额外训练开销可以做得很小
第二个是 SwiGLU Clamping。报告说,他们发现把 SwiGLU 的 linear component 限制在 [-10, 10],并把 gate component 的上界限制在 10,可以有效去掉 outlier,提升稳定性,而且不损伤性能。
这点别忽略。PDF 在结尾没有把这两招写成“原理已经完全解释清楚”,而是明确说 Anticipatory Routing 和 SwiGLU Clamping 虽然有效,但 underlying principles 还没有被充分理解。(原文第 27 页、第 45 页)
7. 后训练主线:specialist training、OPD 和 Think 模式
原文对应:第 29-31 页、第 41 页。
post-training 这一段延续了 V3.2 的大框架,但有一个明确变化:mixed RL stage 被完整替换成了 On-Policy Distillation (OPD)。
整体流程分两步:
- 先训练不同领域的 specialist model
- 再通过
OPD把这些能力整合回统一模型
PDF 明确列出的 specialist 方向包括:
- mathematics
- coding
- agent
- instruction following
这些 specialist 的训练流程是:
- 先做
SFT - 再做
RL - RL 算法使用
GRPO
在 hard-to-verify task 上,报告还提到 Generative Reward Model (GRM)。这里的做法不是把 GRM 当成外部裁判,而是让 actor network 原生承担 GRM 角色,把 judging 和 generation 一起训练。(原文第 29 页)
7.1 Think 模式不是一句营销词
报告明确说,DeepSeek-V4-Pro 和 Flash 都支持三种 reasoning effort mode:
Non-thinkThink HighThink Max
PDF 的解释是,这三种模式在 RL 训练里用了不同的 length penalty 和 context window,所以会对应不同的 reasoning token 长度。为了把这些模式装进同一个模型,V4 使用 <think> 和 </think> 作为特定 response format。
对 Think Max,PDF 的描述也很具体:system prompt 开头会注入额外指令,要求模型更彻底地分解问题、写出完整推理过程,并检查 edge case 和 adversarial scenario。
工具调用部分,报告还加入了新的 |DSML| special token 和 XML-based tool-call schema,理由是这种格式可以减少 escaping failure 和 tool-call error。
7.2 interleaved thinking 改了什么
还有一个变化值得单独说:interleaved thinking。
V3.2 的策略是:tool-result round 之间会保留 reasoning trace,但只要来了新的 user message,旧 reasoning content 就会丢掉。V4 借助 1M context,把这个策略改细了:
- 在 tool-calling scenario 里,完整 reasoning history 会跨轮保留
- 在 general conversation 里,来了新的 user message 以后,旧 reasoning content 仍然会被丢弃
PDF 还补了一个限制条件:如果 agent framework 把 tool interaction 模拟成 user message,例如 Terminus,这种 reasoning persistence 可能不会生效,所以这类架构仍建议使用 non-think model。(原文第 30-31 页)
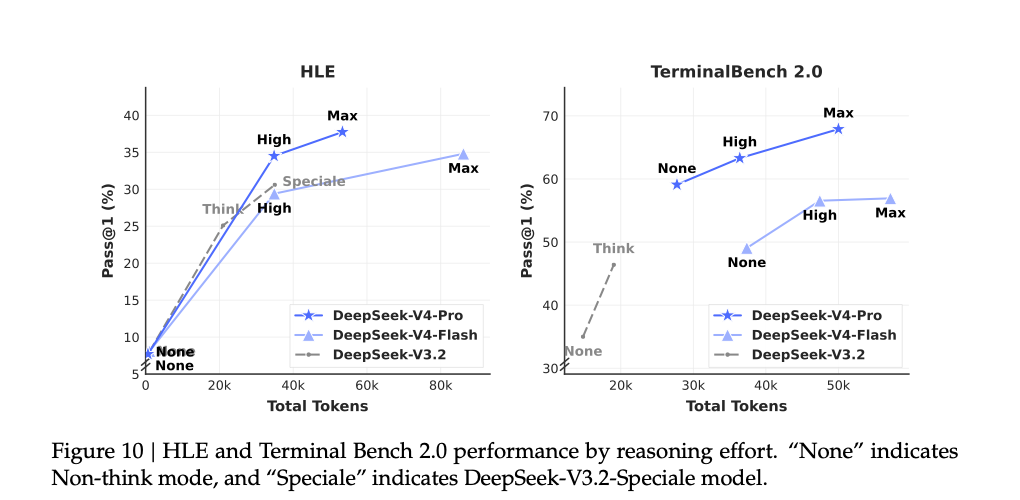
原文第 41 页 Figure 10:同一个模型拿到更多 reasoning budget 后,HLE 和 TerminalBench 2.0 的结果会继续往上走。
8. 结果怎么看:比起总榜,更该看接近真实工作的任务
原文对应:第 5-6 页、第 41-44 页、第 57-58 页。
如果只看 PDF 的 summary,官方对能力分布的描述大致是:
Knowledge:DeepSeek-V4-Pro-Max在SimpleQA、Chinese-SimpleQA上显著超过领先开源模型,在MMLU-Pro、HLE、GPQA这类教育知识评测上对开源模型保持小幅领先,但仍落后于Gemini-3.1-ProReasoning:超过GPT-5.2和Gemini-3.0-Pro,但略低于GPT-5.4和Gemini-3.1-ProAgent:和Kimi-K2.6、GLM-5.1这类领先开源模型大致同级,略弱于 frontier closed model;在 internal evaluation 里超过Claude Sonnet 4.5,并接近Opus 4.5Long-Context:在1M context的 synthetic 和 real use case 上结果很强,在 academic benchmark 上超过Gemini-3.1-ProFlash vs Pro:Flash-Max因为参数更小,knowledge 偏弱,但在给足 thinking budget 后,reasoning 结果可以接近GPT-5.2和Gemini-3.0-Pro
PDF 还给了一句很具体的判断:和最前沿闭源模型相比,reasoning 大约还有 3 到 6 个月 的差距。官方报告里会这样写,其实已经算克制。(原文第 5-6 页)
8.1 中文写作:功能写作更稳,复杂约束任务仍有差距
原文对应:第 57-58 页。
real-world task 这一章先讲中文写作。这里最值得看的一点是,它没有只给一个总分,而是把功能写作、创意写作、复杂指令跟随和多轮写作拆开评估。
在中文功能写作里,PDF 给出的 pairwise result 是:
DeepSeek-V4-Pro对Gemini-3.1-Pro的总体胜率为62.7%Gemini-3.1-Pro为34.1%
报告对这个结果的解释也写得很直接:Gemini 在中文写作场景里,有时会让自己的 stylistic preference 盖过用户的 explicit requirement。(原文第 57 页)
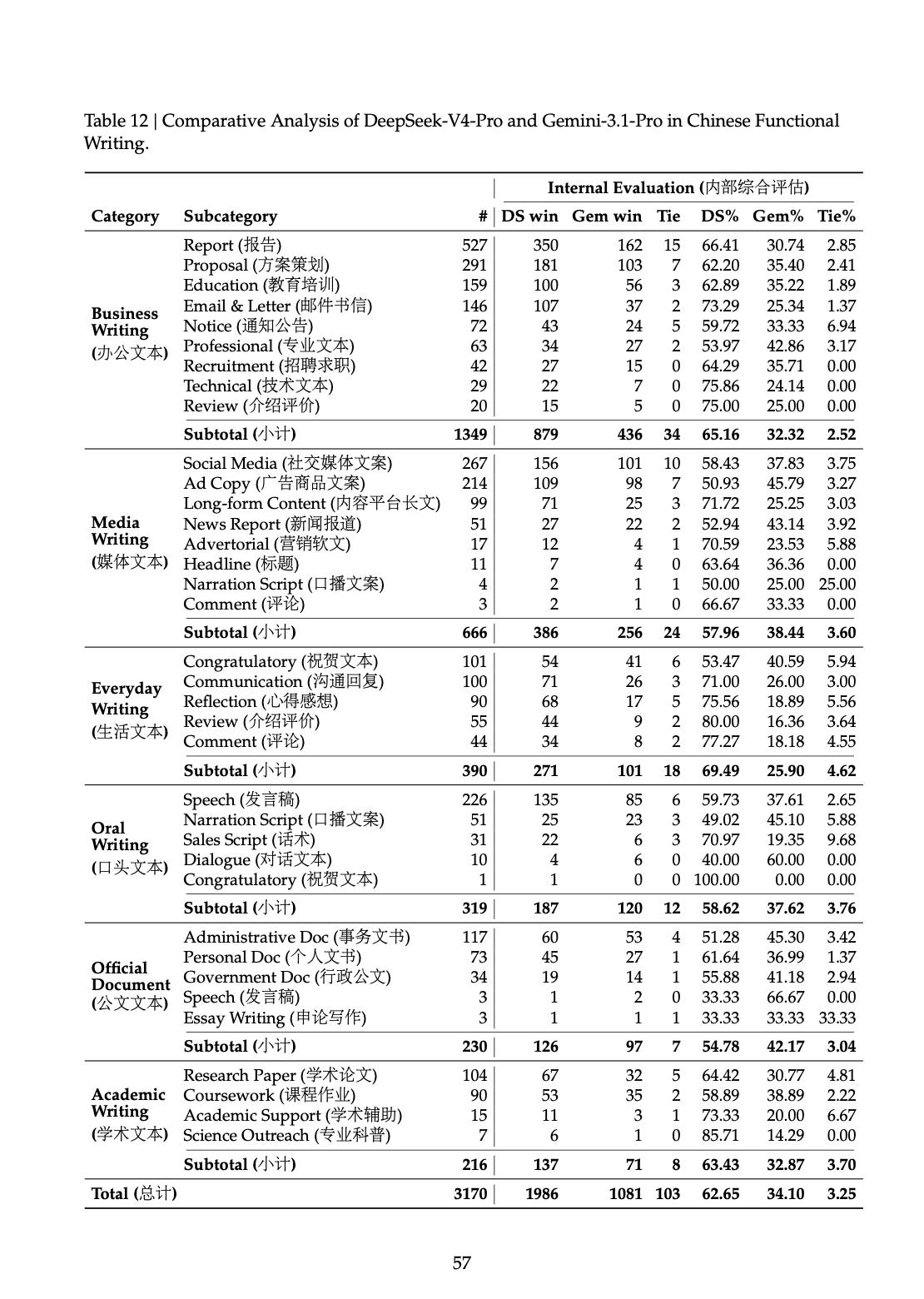
原文第 57 页 Table 12:中文功能写作的分项结果,能看到各种子任务下的胜负分布。
creative writing 部分,PDF 拆成两个维度:
- instruction following:
60.0% - writing quality:
77.5%
这点很重要。它说明报告自己也没有把“写得好”和“按要求写”混成一件事,而是分开看。(原文第 58 页)
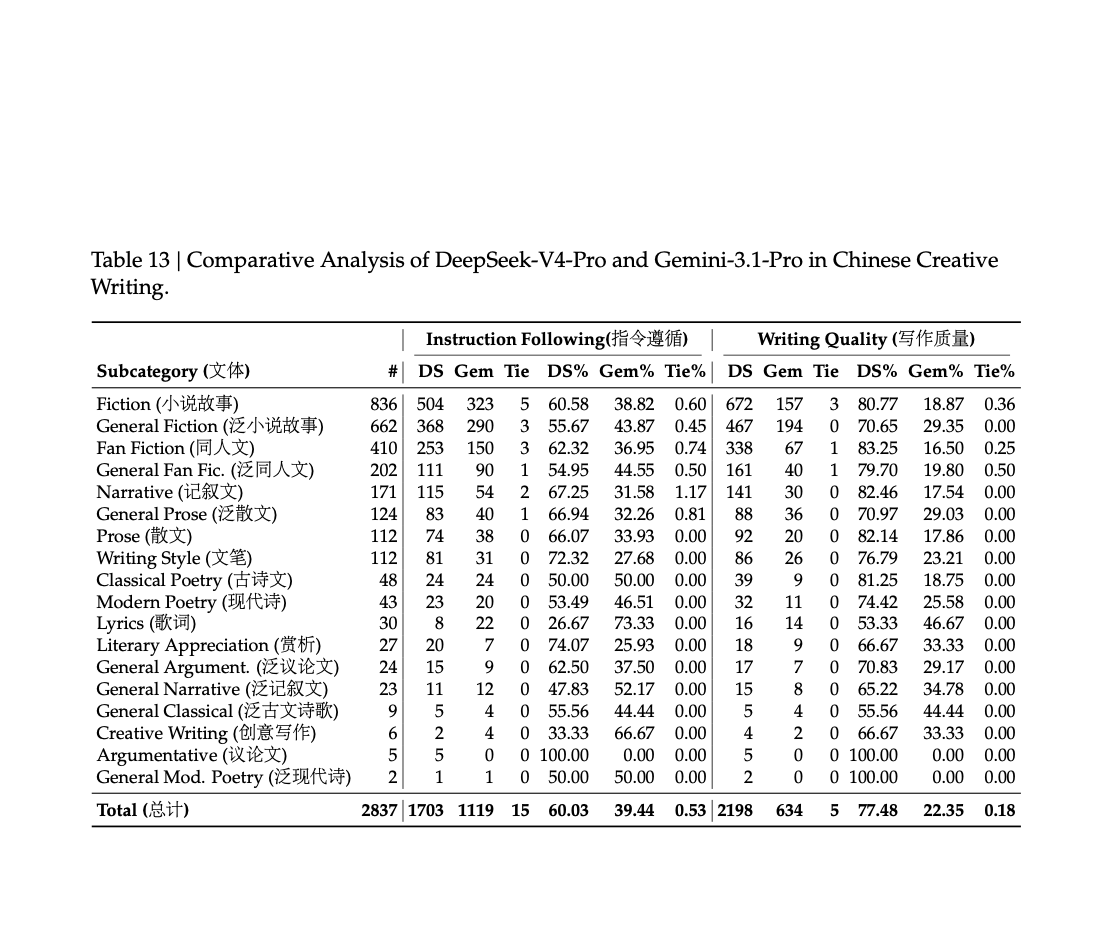
原文第 58 页 Table 13:创意写作里,PDF 同时比较了 instruction following 和 writing quality 两个维度。
但 PDF 也没有把结果写得太满。在最高复杂度约束和多轮写作任务上,Claude Opus 4.5 仍然领先,结果是:
Claude Opus 4.5:52.0%DeepSeek-V4-Pro:45.9%
这组数字提醒得很清楚:V4 的中文写作已经很强,但碰到复杂约束、多轮持续一致这类更难的场景,报告自己也承认还没领先到头。(原文第 58 页)
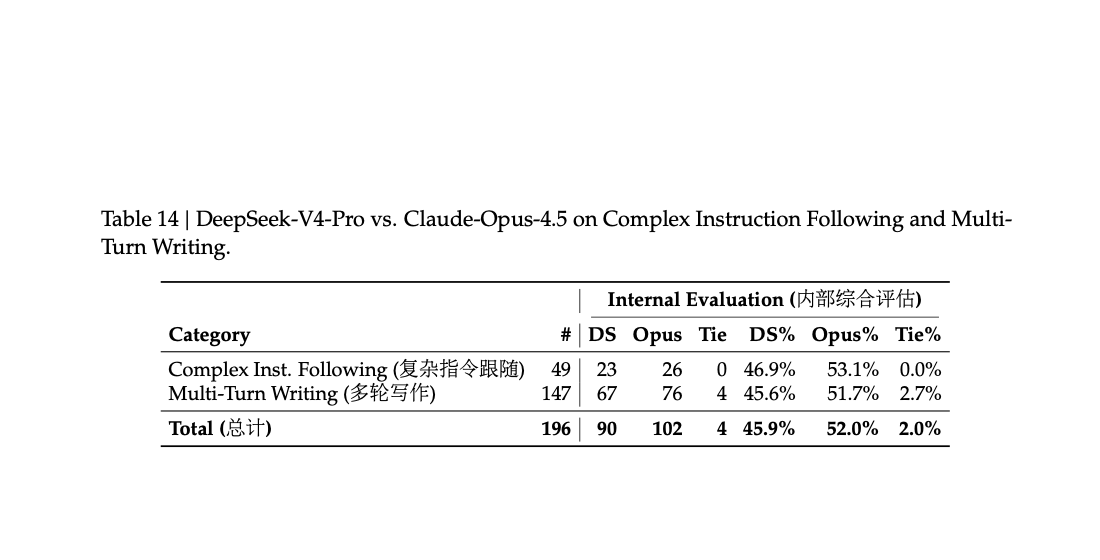
原文第 58 页 Table 14:复杂指令跟随和多轮写作这两类高约束任务里,Opus 4.5 仍占优。
8.2 White-collar task:更接近日常办公,而不是标准化题库
原文对应:第 43 页。
white-collar task 这一节,我觉得参考价值挺高。PDF 说他们构造了 30 个高级中文职业任务,覆盖 13 个行业,在自研 agent harness 里评估,工具包括 Bash 和 web search。
对比对象是 Opus-4.6-Max。最终结果里,DeepSeek-V4-Pro-Max 的 non-loss rate 为 63%。
人工评估用了四个维度:
Task CompletionInstruction FollowingContent QualityFormatting Aesthetics
报告对结果的总结也很具体:
- 强项主要在
Task Completion和Content Quality - 模型会主动补充信息和自校验
- 长文生成能力更强,输出更完整连贯
- 在中文正式结构上更规范
同时,PDF 也写明了短板:
- 有时会漏掉特定格式约束
- 不太擅长把长文本压成很短的摘要
- 幻灯片类输出的视觉排版还有提升空间
这部分好就好在,它不只是给一个胜率,还顺手告诉你模型赢在哪,又卡在哪。(原文第 43 页)
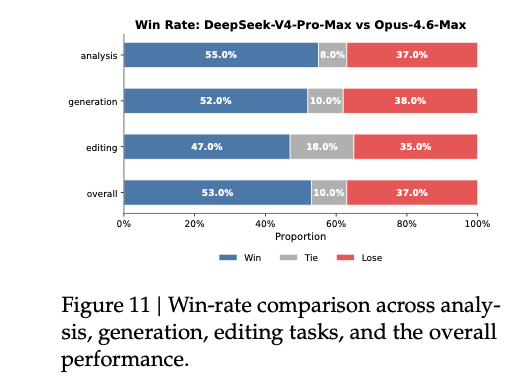
原文第 43 页 Figure 11:white-collar task 的整体 win / tie / lose 分布。
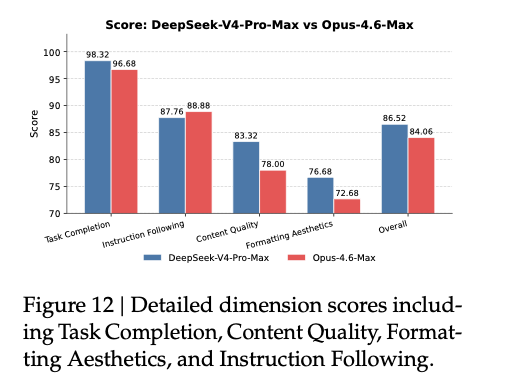
原文第 43 页 Figure 12:不同评分维度上的相对表现,重点能看到完成度、内容质量和格式美观度的差异。
8.3 Code Agent:不是公开小题库,而是内部真实研发任务
原文对应:第 44 页。
code agent 这一节,PDF 用的不是公开小 benchmark,而是内部真实研发任务:
- 原始任务约
200个 - 来自
50+名内部工程师 - 覆盖 feature development、bug fixing、refactoring、diagnostics
- 技术栈包括
PyTorch、CUDA、Rust、C++ - 经过质量筛选后,最终保留
30个任务做评测
对应的 pass rate 是:
Haiku 4.5:13Sonnet 4.5:47DeepSeek-V4-Pro-Max:67Opus 4.5:70Opus 4.5 Thinking:73Opus 4.6 Thinking:80
PDF 对这个结果的总结很明确:DeepSeek-V4-Pro 明显超过 Claude Sonnet 4.5,并接近 Claude Opus 4.5。(原文第 44 页)

原文第 44 页 Table 8:内部研发 coding benchmark 的 pass rate 对比。
报告还给了一项内部调查。对 85 名有日常 agentic coding 使用经验的 DeepSeek 开发者和研究员:
52%认为DeepSeek-V4-Pro已经可以作为默认和主要 coding model39%倾向于认为可以- 不到
9%认为不可以
PDF 也同步记录了几个问题点:trivial mistake、对模糊 prompt 的误解,以及 occasional over-thinking。这个细节有价值,因为它让整段评测更像真实使用反馈,而不是单向表扬稿。(原文第 44 页)
9. 最后看限制:这恰好是报告比较可信的地方
原文对应:第 44-45 页。
结论部分没有把 V4 写成一个已经完全收束的版本。PDF 明确写到:
- 为了追求 extreme long-context efficiency,V4 使用了很多 preliminarily validated component 和 trick
- 这些设计虽然有效,但让整体架构相对复杂
- 后续还要做更 principled 的 investigation,把结构继续压到更 essential 的 design
报告列出的后续方向包括:
- 探索新的 sparsity dimension,例如更 sparse 的 embedding module
- 持续研究 low-latency architecture 和 system technique
- 继续推进 long-horizon、multi-round agentic task
- 引入 multimodal capability
- 改进 data curation 和 synthesis strategy
按这份 technical report 的主线去看,DeepSeek-V4 讲的不是“又做了一个更大的模型”,而是一套围绕 1M context efficiency、training stability、tool use 和 real-world task 展开的完整技术方案。
我读完后印象最深的,也不是某个单独数字,而是这条主线很顺:先承认超长上下文的成本问题,再用 CSA/HCA、mHC、Muon 和一整套系统实现去压成本,最后拿中文写作、white-collar task、code agent 这些更接近真实工作的场景来验证,同时把短板也写出来。
所以这份 PDF 值得读。它不像一篇只报喜不报忧的发布稿,更像一份认真回答“我们到底改了什么、为什么这么改、现在做到哪一步了”的技术说明书。
读完 DeepSeek-V4 技术报告:这次最值得看的,不是“更大”,而是“更省”




