读完 DeepSeek-V4 技术报告:这次最值得看的,不是“更大”,而是“更省”
先说清楚边界。本文只基于 deepseek-v4/DeepSeek_V4.pdf,不补 PDF 外的传闻,也不把报告里没有展开的内容写成确定结论。
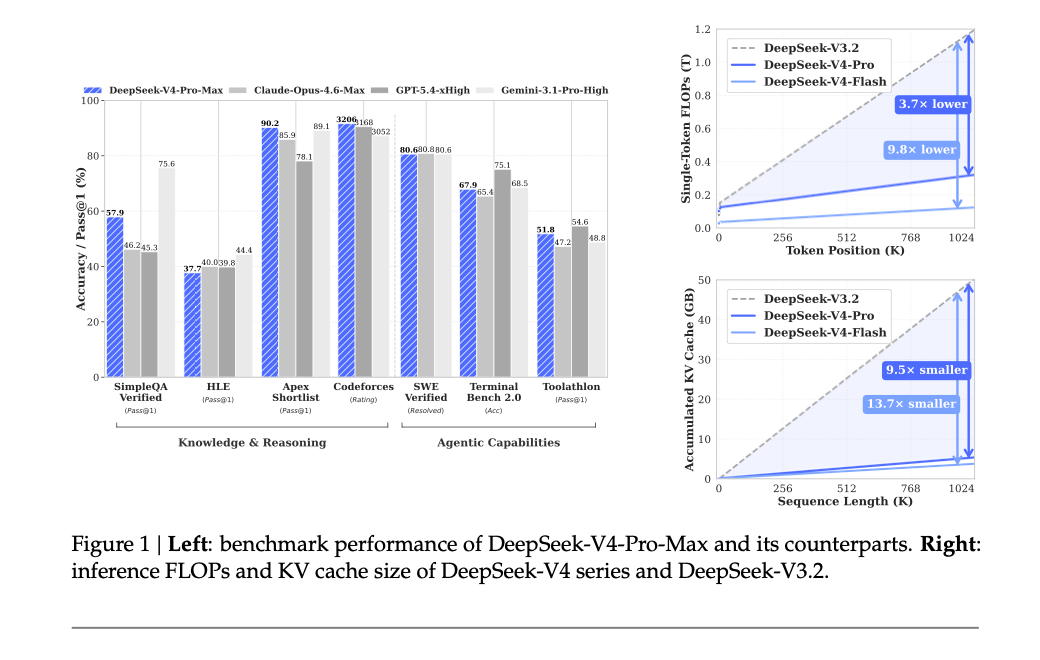
如果只用一句话概括,我会这么说:DeepSeek-V4 要解决的核心问题,不是“参数再大一点”,而是模型真的开始跑超长上下文、长链路推理和复杂工具调用时,传统 attention 的成本会先撑不住。V4 的很多改动,最后都指向同一个问题:1M context 到底怎样才能跑起来,而且别贵得离谱。(原文第 4-5 页)
文中提到的“原文第 X 页”,都对应 DeepSeek_V4.pdf 的 PDF 页码。中文写作、white-collar task、code agent 这些结果,多数来自报告里的 internal evaluation,更适合看作“官方自测结果”,不应直接等同于第三方独立评测。(原文第 43-44 页、第 57-58 页)


